ML 기술들이 발전함에 따라서 가장 많이 변한 부분 중 하나는 normalization 기술이라고 생각합니다.
최근 ML Computer Vision 분야에서 프로덕트화 해야하는 일을 하고 있는데 1%의 성능이라도 소중하다 보니 찾아보고 적용해보면서 생각보다 퍼포먼스에 큰 영향을 주는 부분이라는 것을 깨닳아서 이렇게 정리하게 되었습니다.
# 개요
normalization 기술을 정리함에 있어서 기술들의 유사한 부분과 차이가 있는 부분들을 정리하는 것이 제일 이해하기도 쉽고 사용할 때 필요한 기술을 선택하기도 쉽다고 생각합니다. 이 글에서는 이 부분들을 중점적으로 정리해보고자 합니다.
cvpr 2021 에서 굉장히 좋은 survey 논문이 있어서 이 논문을 정리하는 식의 포스팅이 될 것 같습니다.
# 논문
"Normalization Techniques in Training DNNs: Methodology, Analysis and Application" (by Lei Huang, Jie Qin, Yi Zhou, Fan Zhu, Li Liu, Ling Shao)
# 서론
- linear mapping with learnable parameters 와 non linear activation function 가 여러 번 중첩 (stacked) 되어 있는 형태의 deep neural network는 데이터에서 feature를 추출하고 원하는 결과를 도출해 낼 수 있게 해주었으며, 이러한 결과는 deep 구조 덕분도 있지만 training techniques (optimization (ex., Adam), activation function (ex., ReLU), normalization (ex., batch normalization) 의 발전이 가장 중요한 요소입니다.
- normalization 방법은 (1) 학습의 안정성 (2) 학습의 효율성 (3) 일반화 능력 의 증가를 보여주는 대표적인 training technique입니다.
# 기본적인 Normalization 방법들
- 이 논문에서는 5가지의 normalization operation에 대해서 먼저 정리를 하고 있습니다.
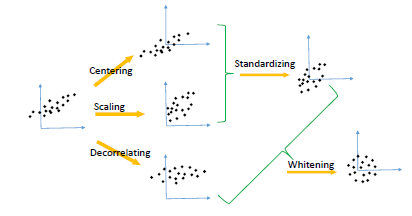
- Centering
- Scaling
- Decorrelating
- Standardization
- Whitening
- Centering 은 normalized 된 데이터가 a zero-mean property, 즉 평균값이 0이 되도록 하는 방법을 의미합니다.

- Scaling 은 normalized 된 데이터가 a unit-variance property, 즉 분산 값이 1이 되도록 하는 방법을 의미합니다.


Scaling은 쉽게 말해 분산을 1로 두는 것으로 분산은 다 아시는 것처럼 값들의 평균을 구하고 그 값들의 제곱을 다 더하고 다시 평균을 낸 값입니다. 주로 여러 입력값들이 있는데 그 수치의 크기가 달라서 큰 수의 값에 신경망이 지나치게 영향을 받는 것을 방지하기 위해서 사용됩니다.[2]
- Decorrelating 은 normalized 된 데이터의 다른 feature 간의 correlation이 0 이 되도록 하는 방법입니다.


- Standardization 은 위에서 언급한 Centering과 Scaling 을 결합한 방법입니다. 즉, 평균이 0 이고 분산이 1인 데이터로 데이터를 변환하는 방법입니다.

- Whitening 은 normalized 된 데이터가 spherical Gaussian distribution을 따르도록 하는 방법입니다.
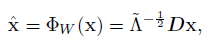
위 식의 Whitening은 principal components analysis (PCA) whitening의 형태입니다. 이 방법의 특징은 데이터의 각 feature 간에 (1) 서로 작은 correlation를 지니도록 하며 feature들이 모두 (2) 동일한 분산 variance을 가지도록 하는 방법입니다. [3] correlation을 줄이기 위해서 D 라는 데이터의 eigen-vector들로 구성된 matrix를 곱해준 뒤, variance를 동일하게 만들기 위해서 Scaling을 수행합니다.
# Neural Network에서의 Normalization 방법들
1. Normalize activations using the population statistics
이 방법에는 대표적으로 training dataset이 만들어 내는 activation 값의 평균 값을 계산하여 layer x의 activation 값 'x'를 Centering 하는 방법입니다.

다른 방법으로는 mini-batch를 사용하여 학습을 하면서 학습에 사용 된 batch 내의 데이터들이 만들어 내는 activation 값의 평균 값을 위의 수식에 따라서 Centering 하는 방법입니다. 다만, iteration이 진행됨에 따라 이전의 mean 값에 새롭게 본 mini-batch 내의 데이터의 평균까지 더해서 지속적으로 update하는 방법이 있습니다.
위의 대표적인 논문은 다음과 같습니다.
- S. Wiesler, A. Richard, R. Schl¨uter, and H. Ney, “Mean-normalized stochastic gradient for large-scale deep learning,” in ICASSP, 2014.
- G. Montavon and K.-R. M¨uller, Deep Boltzmann Machines and the Centering Trick, 2012, vol. 7700.
2. Normalize activations as Functions
이 방법의 대표적인 방법으로는 Batch Normalization (BN)이 있습니다. BN은 mini-batch 단위의 데이터가 ML 모델에 입력될 때, 입력 된 mini-batch단위가 중간 layer를 지날 때 activation의 output에 대해서 standardization을 수행합니다.


BN은 inference time에 deterministic 하게 동일한 normalization이 수행될 수 있도록 하기 위해서 training iteration 동안 running average 방법을 통해서 mean과 variance를 계산하여 사용합니다.

이때, BN은 위의 정규화 과정 이외에도 γ 와 β 라는 learnable parameter 가 존재합니다. 이 변수들은 아래의 sigmoid 함수와 같은 역할을 하는 layer가 있고 BN이 이 layer의 input을 정규화 한다고 가정하였을 때 지속적으로 0 ~ 1 사이의 값만이 해당 layer에게 전달되어 layer들이 쌓여 비선형 성을 갖는 것을 방해하는 경우를 해결하기 위해서 affine transformation을 수행할 수 있도록 하는 변수입니다. [2]

이렇게 BN은 1. Normalize activations using the population statistics 에서 제시한 방법들과는 달리 mini-batch 단위로 정규화를 수행하여 가지고 있는 데이터 셋을 통한 estimation이 아니라 입력된 데이터에 대한 mean과 std를 사용하는 방식으로 mini-batch의 output에 대해서 activation의 분포가 안정화시켜 학습이 효과적으로 이루어질 수 있도록 합니다.
하지만, BN의 큰 단점은 다음과 같이 2가지가 있습니다.
- inference시에 operation이 다르게 작동하여 performance에 불안정성이 존재
- small batch size를 사용하는 경우 학습과정 및 inference시에 error가 큼 (input data에 대한 mean & std 가 mini-batch 단위로 수행되어 학습에 사용됨)
이제 이런 문제를 가진 BN을 대체하기 위한 많은 Normalize activations as Functions 방법들에 대해서 살펴보도록 하겠습니다. 해당 내용은 포스팅 길이 문제로 다음 포스트에서 다루도록 하겠습니다.
# References
[1] https://eehoeskrap.tistory.com/430
[2] https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=magnking&logNo=221164336924
[3] https://withkairos.wordpress.com/2015/06/13/ufldl-tutorial-8-whitening/
'ML' 카테고리의 다른 글
| [Activation Functions] (0) | 2022.06.09 |
|---|---|
| [Normalization Techniques] 2탄 Decomposing Normalization (0) | 2022.05.30 |
| [GluonCV, OpenSource 분석하기] GluonCV의 multiprocessing 이해하기 [2] (0) | 2021.10.27 |
| [GluonCV, OpenSource 분석하기] GluonCV의 multiprocessing 이해하기 [1] (0) | 2021.10.27 |
| Pytorch Distributions Shape 의 이해(Understanding Shapes in Pytorch Distribution) (0) | 2021.10.11 |

